Bagian 10
SPSS UNTUK PENGUJIAN HIPOTESIS
A. Uji Hipotesis Satu Sampel
Hipotesis adalah pernyataan mengenai sesuatu yang akan dibuktikan kebenarannya lewat penelitian. Untuk menguji hipotesis, langkah pertama yang harus dilakukan adalah merumuskan hipotesis. Rumusan hipotesis tersebut biasanya dinyatakan dalam bentuk hipotesis null dan hipotesis alternatif.
Uji satu sampel untuk rata-rata digunakan untuk menguji rata-rata sampel apakah sesuai dengan rata-rata populasi. Pengujian ini dilakukan untuk memperoleh keyakinan atas nilai rata-rata suatu sampel.
B. Uji Satu Sampel untuk Rata-Rata dengan Aplikasi SPSS
Tahap-tahap pengujian menggunakan program SPSS adalah sebagai berikut:
1. Masukkan data dalam jendela Data View SPSS dengan cara yang sama di mana semua data dikelompokkan dalam satu variabel. Beri nama variabel dengan skor, kemudian isi label dengan Skor TOEFL Mahasiswa.
2.Dari menu Analyze, pilih menu Compare Means, kemudian pilih One-Sampel T Test sehingga keluar jendela berikut.
3. Masukkan variabel skor TOEFL mahasiswa dalam kolom Test Veriable.
4. Abaikan menu yang lain.
5. Klik tombol OK.
C. Uji Hipotesis Dua Sampel
D. Uji t Dua Sampel yang Berpasangan Menggunakan SPSS
Rabu, 02 Mei 2018
Rabu, 25 April 2018
Bagian 9
Penggunaan SPSS Untuk Menghitung Validitas dan Reabilitas Data
A. Uji Validitas
Uji validitas dilakukan untuk memastikan seberapa baik suatu instrumen dan untuk mengukur konsep yang harusnya diukur. Sugiyono (2010) untuk menguji validitas dilakukan dengan cara mengkorelasikan antara skor butir pertanyaan dengan skor totalnya.
B. Uji Reabilitas
Suharsimi Arikunto (2006 : 154)
Reabilitas menunjuk pada suatu pengertian bahwa sesuatu instrumen cukup dapat dipercaya untuk digunakan sebagai alat pengumpul data karena instrumen tersebut sudah baik.
C. SPSS (Statistical Product and Service Solution)
merupakan sebuah program aplikasi yang mempunyai kemampuan untuk menganalisis statistik dengan keakuratan yang cukup tinggi.
৹Sejarah SPSS
SPSS dibuat pertama kali pada tahun 1968 oleh tiga mahasiswa Standford University, yaitu Norma H. Nie, C. Hadlai Hull dan Dale H. Bent. Awalnya SPSS diciptakan untuk proses mengolah data dalam Ilmu sosial dengan kepanjangan Statistical Package for the Social Science. Namun sekarang fungsi SPSS sudah diperluas untuk menjalankan berbagai jenis kebutuhan, seperti mengolah produksi barang, hasil reset dll. Singkatan SPSS pun berubah menjadi Statistical Product and Service Solution.
৹Fungsi SPSS
1. Melakukan riset pemasaran (market research)
2. Pengendalian dan perbaikan mutu (quality improvement)
3. Analisis data survey atau kuisioner
4. Banyak digunakan dalam penelitian akademik mahasiswa
5. Banyak digunakan untuk keperluan pemerintah (seperti lembaga BPS)
6. Penelitian kesehatan rakyat dan lain-lain
Penggunaan SPSS Untuk Menghitung Validitas dan Reabilitas Data
A. Uji Validitas
Uji validitas dilakukan untuk memastikan seberapa baik suatu instrumen dan untuk mengukur konsep yang harusnya diukur. Sugiyono (2010) untuk menguji validitas dilakukan dengan cara mengkorelasikan antara skor butir pertanyaan dengan skor totalnya.
B. Uji Reabilitas
Suharsimi Arikunto (2006 : 154)
Reabilitas menunjuk pada suatu pengertian bahwa sesuatu instrumen cukup dapat dipercaya untuk digunakan sebagai alat pengumpul data karena instrumen tersebut sudah baik.
C. SPSS (Statistical Product and Service Solution)
merupakan sebuah program aplikasi yang mempunyai kemampuan untuk menganalisis statistik dengan keakuratan yang cukup tinggi.
৹Sejarah SPSS
SPSS dibuat pertama kali pada tahun 1968 oleh tiga mahasiswa Standford University, yaitu Norma H. Nie, C. Hadlai Hull dan Dale H. Bent. Awalnya SPSS diciptakan untuk proses mengolah data dalam Ilmu sosial dengan kepanjangan Statistical Package for the Social Science. Namun sekarang fungsi SPSS sudah diperluas untuk menjalankan berbagai jenis kebutuhan, seperti mengolah produksi barang, hasil reset dll. Singkatan SPSS pun berubah menjadi Statistical Product and Service Solution.
৹Fungsi SPSS
1. Melakukan riset pemasaran (market research)
2. Pengendalian dan perbaikan mutu (quality improvement)
3. Analisis data survey atau kuisioner
4. Banyak digunakan dalam penelitian akademik mahasiswa
5. Banyak digunakan untuk keperluan pemerintah (seperti lembaga BPS)
6. Penelitian kesehatan rakyat dan lain-lain
Jumat, 06 April 2018
Bagian 7
Validitas dan Reliabilitas Instrumen Penelitian
Validitas
Ridwan (2016) menyebutkan validitas adalah suatu ukuran yang menunjukan suatu kevalidan dan atau kesahlihan suatu instrumen.
Suatu instrumen yang valid apabila:
1. Mempunya validitas tinggi. Bila validitasnya rendah maka instrumen tersebut kurang valid.
2. Mampu mengukur apa yang hendak diukur atau diinginkan.
3. Dapat mengungkap data dari variabel yang dapat diteliti.
Pengujian validitas internal:
-Pengujian validitas konstruk (constract validity)
Setelah instrumen dikonstruksi tentang aspek-aspek yang akan diukur dengan berlandaskan teori tertentu, maka selanjutnya dikonsultasikan dengan pendapat para ahli (judgment experts). Instrumen yang telah disetujui para ahli tersebut dicoba pada sampel dari mana populasi diambil.
-Validitas isi (content validity)
Dilakukan dengan membandingkan antara isi instrumen dengan materi pelajaran yang telah diajarkan.
-Pengujian validitas eksternal
Validitas eksternal instrumen diuji dengan cara membandingkan antara kriteria yang ada pada instrumen dengan fakta empiris yang terjadi di lapangan. Bila terdapat kesamaan antara kriteria dalam instrumen dengan fakta di lapangan, maka dapat dinyatakan instrumen tersebut mempunya validitas eksternal yang tinggi.
Reliabilitas
Realibilitas menunjuk pada suatu pengertian bahwa suatu instrumen dapat dipercaya untuk digunakan sebagai alat pengumpul data karena instrumen tersebut sudah dianggap baik.
Reliabel juga dipercaya dapat diandalkan. Sehingga beberapa kali di ulang pun hasilnya akan tetap sama (konsisten).
Pengujian reliabilitas secara eksternal:
1. Test-retest
Test-retest dilakukan dengan cara mencoba instrumen beberapa kali pada responden. Jadi dalam hal ini instrumennya sama, respondennya sama, dan waktunya yang berbeda. Reliabilitas diukur dari koefisien korelasi antara percobaan pertama dengan yang berikutnya. Bila koefisien korelasi positif dan signifikan maka instrumen tersebut sudah dinyatakan reliabel.
Contoh:
Akan dilakukan penelitian tentang kemampuan kerja pegaai di PTS. Untuk pengukuran kerja pegawai akan dilakukan instrumen dengan skala Likert. Sebelum instrumen tersebut digunakan untuk pengukuran yang sebenarnya, akan di uji reabilitas terlebih dahulu. Untuk keperluan tersebut peneliti melakukan uji coba instrumen yang sama banyaknya dua kali. Hasil yang diperoleh dari dua kali uji coba tersebut sebagai berikut.
2. Equivalen
Instrumen yang equivalen adalah pertanyaan yang secara bahsa berbeda, tetapi maksudnya sama.
Contoh:
Berapa tahun anda sudah belajar bahasa Korea?
Tahun berapa anda mulai belajar bahasa Korea?
Pengujian reabilitas instrumen dengan cara ini cukup dilakukan sekali, tetapi instrumennya dua, pada responden yang sama, waktu sama, instrumen berbeda. Reliabilitas instrumen dihitung dengan cara mengkorelasikan antara data instrumen yang satu dengan data instrumen yang dijadikan equivalen.
3. Gabungan (test-retest dan equivalen)
Pengujian reliabilitas ini dilakukan dengan cara mencoba dua instrumen yang equivalen beberapa kali ke responden yang sama. Reliabilitas instrumen dilakukan dengan mengkorelasikan dua instrumen, setelah itu dikorelasikan secara silang. Hal ini dapat digambarkan sebagai berikut:
Pengujian reliabilitas secara internal:
Pengujian reliabilitas dengan internal consistency, dilakukan dengan cara mencobakan instrumen sekali saja, kemudian hasil analisis dapat digunakan untuk memprediksi reliabilitas instrumen. Pengujiannya dapat dilakukan dengan teknik belah dua dari Spearman Brown (Split half), KR 20, KR 21, dan Anova Hoyt. Berikut rumus-rumus dan contoh perhitungannya.
1. Rumus Spearman Brown
2. Rumus KR 20 (Kuder Richardson)
3. Rumus KR 21
4. Alda Cronbach
Pengujian reliabilitas dengan teknik Alfa Cronbach dilakukan untuk jenis data interval/essay. Rumus koefisien reliabilitas Alfa Cronbach:
Validitas dan Reliabilitas Instrumen Penelitian
Validitas
Ridwan (2016) menyebutkan validitas adalah suatu ukuran yang menunjukan suatu kevalidan dan atau kesahlihan suatu instrumen.
Suatu instrumen yang valid apabila:
1. Mempunya validitas tinggi. Bila validitasnya rendah maka instrumen tersebut kurang valid.
2. Mampu mengukur apa yang hendak diukur atau diinginkan.
3. Dapat mengungkap data dari variabel yang dapat diteliti.
Pengujian validitas internal:
-Pengujian validitas konstruk (constract validity)
Setelah instrumen dikonstruksi tentang aspek-aspek yang akan diukur dengan berlandaskan teori tertentu, maka selanjutnya dikonsultasikan dengan pendapat para ahli (judgment experts). Instrumen yang telah disetujui para ahli tersebut dicoba pada sampel dari mana populasi diambil.
-Validitas isi (content validity)
Dilakukan dengan membandingkan antara isi instrumen dengan materi pelajaran yang telah diajarkan.
-Pengujian validitas eksternal
Validitas eksternal instrumen diuji dengan cara membandingkan antara kriteria yang ada pada instrumen dengan fakta empiris yang terjadi di lapangan. Bila terdapat kesamaan antara kriteria dalam instrumen dengan fakta di lapangan, maka dapat dinyatakan instrumen tersebut mempunya validitas eksternal yang tinggi.
Reliabilitas
Realibilitas menunjuk pada suatu pengertian bahwa suatu instrumen dapat dipercaya untuk digunakan sebagai alat pengumpul data karena instrumen tersebut sudah dianggap baik.
Reliabel juga dipercaya dapat diandalkan. Sehingga beberapa kali di ulang pun hasilnya akan tetap sama (konsisten).
Pengujian reliabilitas secara eksternal:
1. Test-retest
Test-retest dilakukan dengan cara mencoba instrumen beberapa kali pada responden. Jadi dalam hal ini instrumennya sama, respondennya sama, dan waktunya yang berbeda. Reliabilitas diukur dari koefisien korelasi antara percobaan pertama dengan yang berikutnya. Bila koefisien korelasi positif dan signifikan maka instrumen tersebut sudah dinyatakan reliabel.
Contoh:
Akan dilakukan penelitian tentang kemampuan kerja pegaai di PTS. Untuk pengukuran kerja pegawai akan dilakukan instrumen dengan skala Likert. Sebelum instrumen tersebut digunakan untuk pengukuran yang sebenarnya, akan di uji reabilitas terlebih dahulu. Untuk keperluan tersebut peneliti melakukan uji coba instrumen yang sama banyaknya dua kali. Hasil yang diperoleh dari dua kali uji coba tersebut sebagai berikut.
2. Equivalen
Instrumen yang equivalen adalah pertanyaan yang secara bahsa berbeda, tetapi maksudnya sama.
Contoh:
Berapa tahun anda sudah belajar bahasa Korea?
Tahun berapa anda mulai belajar bahasa Korea?
Pengujian reabilitas instrumen dengan cara ini cukup dilakukan sekali, tetapi instrumennya dua, pada responden yang sama, waktu sama, instrumen berbeda. Reliabilitas instrumen dihitung dengan cara mengkorelasikan antara data instrumen yang satu dengan data instrumen yang dijadikan equivalen.
3. Gabungan (test-retest dan equivalen)
Pengujian reliabilitas ini dilakukan dengan cara mencoba dua instrumen yang equivalen beberapa kali ke responden yang sama. Reliabilitas instrumen dilakukan dengan mengkorelasikan dua instrumen, setelah itu dikorelasikan secara silang. Hal ini dapat digambarkan sebagai berikut:
Pengujian reliabilitas secara internal:
Pengujian reliabilitas dengan internal consistency, dilakukan dengan cara mencobakan instrumen sekali saja, kemudian hasil analisis dapat digunakan untuk memprediksi reliabilitas instrumen. Pengujiannya dapat dilakukan dengan teknik belah dua dari Spearman Brown (Split half), KR 20, KR 21, dan Anova Hoyt. Berikut rumus-rumus dan contoh perhitungannya.
1. Rumus Spearman Brown
2. Rumus KR 20 (Kuder Richardson)
3. Rumus KR 21
4. Alda Cronbach
Pengujian reliabilitas dengan teknik Alfa Cronbach dilakukan untuk jenis data interval/essay. Rumus koefisien reliabilitas Alfa Cronbach:
Kamis, 05 April 2018
Bagian 6
Populasi dan Sampel
Populasi
Menurut Sugiyono (2017 : 61) Populasi adalah wilayah generalisasi yang terdiri atas : Obyek/subyek yang mempunyai kuantitas dan karakteristik tertentu yang ditetapkan oleh peneliti untk dipelajari dan kemudian ditarik kesimpulannya.
Sedangkan menurut Furqon (2014 : 146) populasi secara formal dapat didedfinisikan sebagai sekumpulan objek, orang, atau keadaan yang paling tidak memiliki satu karakteristik umum yang sama.
Sampel
Sampel adalah bagian dari jumlah dan karakteristik yang dimiliki oleh populasi. Bila populasi besar, dan peneliti tidak mungkin mempelajari semua yang ada pada populasi, misalnya karena keterbatasan data, tenaga dan waktu, maka peneliti dapat menggunaan sampel yang diambil dari populasi itu (Sugiyono 2017 : 62)
Sedangkan menurut Furqon (2014) secara sederhana sampel berarti bagian dari satu populasi.
Catatan:
Populasi dan sampel umumnya dianggap sebagai kumpulan beberapa individu atau kelompok. Tapi sebenarnya populasi tidak selalau harus terdiri dari lebih dari sastu individu. Seorang individu pun bisa menjadi sebuah populasi. (Sugiyono, 2017 : 62)
Kriteria dan Syarat Pengambilan Sampel
Menurut Sugiyono (2017 : 62) apa yang dipelajari dari sampel, kesimpulannya akan dapat diberlakukan untuk populasi.
Syarat pengambilan sampel adalah populasi harus homogen atau setidaknya memiliki satu karakteristik yang sama. Apabila populasi heterogen, sampel tidak akan representatif (jurnal Unila)
Teknik Sampling
Teknik sampling terbagi dua, yaitu Probability Sampling dan Nonprobability Sampling. Berikut adalah penjelasan tentang teknik sampling menurut Sugiyono (2017 : 63 - 68)
Probability Sampling
- simple random sampling
- proportionate startified random sampling
- disproportionate stratified random sampling
- cluster sampling (area sampling)
Nonprobability Sampling
- sampling sistematis
- sampling kuota
- sampling insidental
- sampling purfosive
- sampling total
- snowball sampling
Menentukan Ukuran Sampel
Rumus untuk menghitung ukuran sampel dan populasi yang tidak diketahui jumlahnya adalah sebagai berikut:
(λ^2 . N. P. Q)/(d^(2 ) (N-1)+ λ^2. P. Q)
Keterangan:
S = jumlah sampel
A² = chi kuadrat yang harganya tergantung derajat kebebasan dan tingkat kesalahan. Untuk derajat kebebasan dan kebebasan 5% harga chi kuadrat = 3,841. Harga chi kuadrat untuk kesalahan 1% = 6,634 dan 10% = 2,706.
N = jumlah populasi
P = peluang benar (0,5)
Q = peluang salah (0,5)
d = perbedaan antara rata-rata sampel dengan rata-rata populasi. Perbedaan bisa 0,01, 0,05, dan 0,10.
Disebutkan dalam Sugiono (2017) Roscoe dalam buku Research Methods For Business (1982 : 253) memberikan saran saran tentang ukuran sampel untuk penelitian seperti berikut ini.
1. Ukuran sampel yang layak dalam penelitian adalah antara 30 sampai dengan 500
2. Bila sampel dibagi dalam kategori, maka jumlah anggota sampel setiap kategori minimal 30.
3. Bila dalam penelitian akan melakukan analisis multivariate (korelasi atau regresi ganda misalnya) maka jumlah anggota sampel minimal 10 kali dari jumlah variabel ang diteliti. Misalnya variabel penelitiannya ada 5 (independen + dependen), maka jumla anggota sampel = 10 x 5 = 50
4. Untuk penelitian eksperimen yang sederhana, yang menggunakan kelompok eksperimen dan kelompok kontrol makan jumlah anggota sampel masing masing kelompok antara lain 10 s/d 20.
Populasi dan Sampel
Populasi
Menurut Sugiyono (2017 : 61) Populasi adalah wilayah generalisasi yang terdiri atas : Obyek/subyek yang mempunyai kuantitas dan karakteristik tertentu yang ditetapkan oleh peneliti untk dipelajari dan kemudian ditarik kesimpulannya.
Sedangkan menurut Furqon (2014 : 146) populasi secara formal dapat didedfinisikan sebagai sekumpulan objek, orang, atau keadaan yang paling tidak memiliki satu karakteristik umum yang sama.
Sampel
Sampel adalah bagian dari jumlah dan karakteristik yang dimiliki oleh populasi. Bila populasi besar, dan peneliti tidak mungkin mempelajari semua yang ada pada populasi, misalnya karena keterbatasan data, tenaga dan waktu, maka peneliti dapat menggunaan sampel yang diambil dari populasi itu (Sugiyono 2017 : 62)
Sedangkan menurut Furqon (2014) secara sederhana sampel berarti bagian dari satu populasi.
Catatan:
Populasi dan sampel umumnya dianggap sebagai kumpulan beberapa individu atau kelompok. Tapi sebenarnya populasi tidak selalau harus terdiri dari lebih dari sastu individu. Seorang individu pun bisa menjadi sebuah populasi. (Sugiyono, 2017 : 62)
Kriteria dan Syarat Pengambilan Sampel
Menurut Sugiyono (2017 : 62) apa yang dipelajari dari sampel, kesimpulannya akan dapat diberlakukan untuk populasi.
Syarat pengambilan sampel adalah populasi harus homogen atau setidaknya memiliki satu karakteristik yang sama. Apabila populasi heterogen, sampel tidak akan representatif (jurnal Unila)
Teknik Sampling
Teknik sampling terbagi dua, yaitu Probability Sampling dan Nonprobability Sampling. Berikut adalah penjelasan tentang teknik sampling menurut Sugiyono (2017 : 63 - 68)
Probability Sampling
- simple random sampling
- proportionate startified random sampling
- disproportionate stratified random sampling
- cluster sampling (area sampling)
Nonprobability Sampling
- sampling sistematis
- sampling kuota
- sampling insidental
- sampling purfosive
- sampling total
- snowball sampling
Menentukan Ukuran Sampel
Rumus untuk menghitung ukuran sampel dan populasi yang tidak diketahui jumlahnya adalah sebagai berikut:
(λ^2 . N. P. Q)/(d^(2 ) (N-1)+ λ^2. P. Q)
Keterangan:
S = jumlah sampel
A² = chi kuadrat yang harganya tergantung derajat kebebasan dan tingkat kesalahan. Untuk derajat kebebasan dan kebebasan 5% harga chi kuadrat = 3,841. Harga chi kuadrat untuk kesalahan 1% = 6,634 dan 10% = 2,706.
N = jumlah populasi
P = peluang benar (0,5)
Q = peluang salah (0,5)
d = perbedaan antara rata-rata sampel dengan rata-rata populasi. Perbedaan bisa 0,01, 0,05, dan 0,10.
Disebutkan dalam Sugiono (2017) Roscoe dalam buku Research Methods For Business (1982 : 253) memberikan saran saran tentang ukuran sampel untuk penelitian seperti berikut ini.
1. Ukuran sampel yang layak dalam penelitian adalah antara 30 sampai dengan 500
2. Bila sampel dibagi dalam kategori, maka jumlah anggota sampel setiap kategori minimal 30.
3. Bila dalam penelitian akan melakukan analisis multivariate (korelasi atau regresi ganda misalnya) maka jumlah anggota sampel minimal 10 kali dari jumlah variabel ang diteliti. Misalnya variabel penelitiannya ada 5 (independen + dependen), maka jumla anggota sampel = 10 x 5 = 50
4. Untuk penelitian eksperimen yang sederhana, yang menggunakan kelompok eksperimen dan kelompok kontrol makan jumlah anggota sampel masing masing kelompok antara lain 10 s/d 20.
Rabu, 14 Maret 2018
Bagian 5
Distribusi Normal dan Standar Deviasi
A. Distribusi Normal
Distribusi Normal atau biasa disebut distribusi gauss adalah salah satu distribusi peluang dengan variable acak kontinu yang paling sering digunakan.

1. Pentingnya Distribusi Normal
Fungsi kerapatan probabilitas dari distribusi normal diberikan dalam rumus berikut:
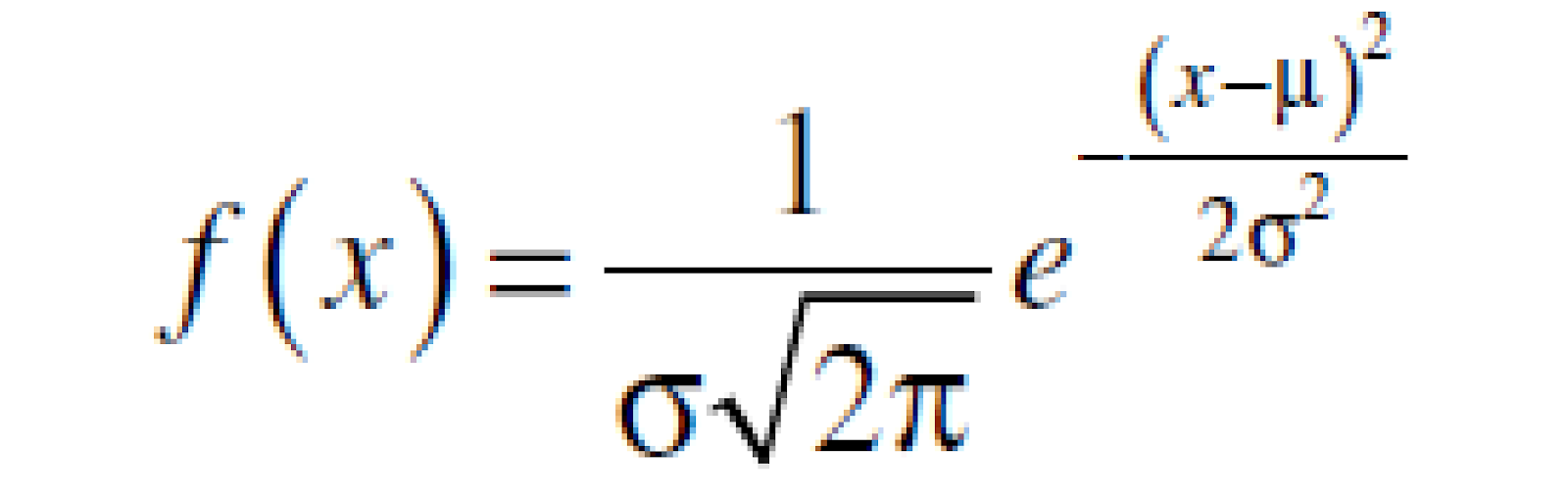




Distribusi Normal dan Standar Deviasi
A. Distribusi Normal
Distribusi Normal atau biasa disebut distribusi gauss adalah salah satu distribusi peluang dengan variable acak kontinu yang paling sering digunakan.
1. Pentingnya Distribusi Normal
- Satu-satunya distribusi probabilitas dengan variabel random kontinu adalah distribusi normal.
- Ada dua peran penting distribusi normal, yaitu :
- Memiliki sifat yang dapat dijadikan satu patokan dalam pengambilan kesimpulan dari beberapa sampel
- Distribusi normal terjadi secara alamiah, banyak peristiwa di dunia nyata yang terdistribusisecara normal.
- π =nilai konstan yang ditulis hingga empat desimal (3,1416)
- e = bilangan konstan, bila ditulis hingga empat desimal e = 2,7183
- µ = parameter, merupakan rata-rata untuk distribusi
- σ = parameter, merupakan simpangan baku untuk distribusi.
Dan nilai x punya batas -∞ < x < ∞, maka dikatakan bahwa variabel acak x berdistribusi normal.
2. Kurva Distribusi Normal
Jika σ makin besar, kurvanya semakin rendah (platikurtik) dan untuk σ makin kecil kurvanya semakin tinggi (leptokurtik).
3. Ciri Distribusi Normal
- Nilai peluang peubah acak dalam distribusi peluang normal dinyatakan dalam luas dari dibawah kurva berbentuk genta atau lonceng (bell shaped curve).
- Kurva maupun persamaan normal melibatkan nilai x, µ, dan σ.
- Keseluruhan kurva yang bernilai 1 akan menggambarkan sifat peluang yang tidak pernah negatif dan maksimal bernilai 1.
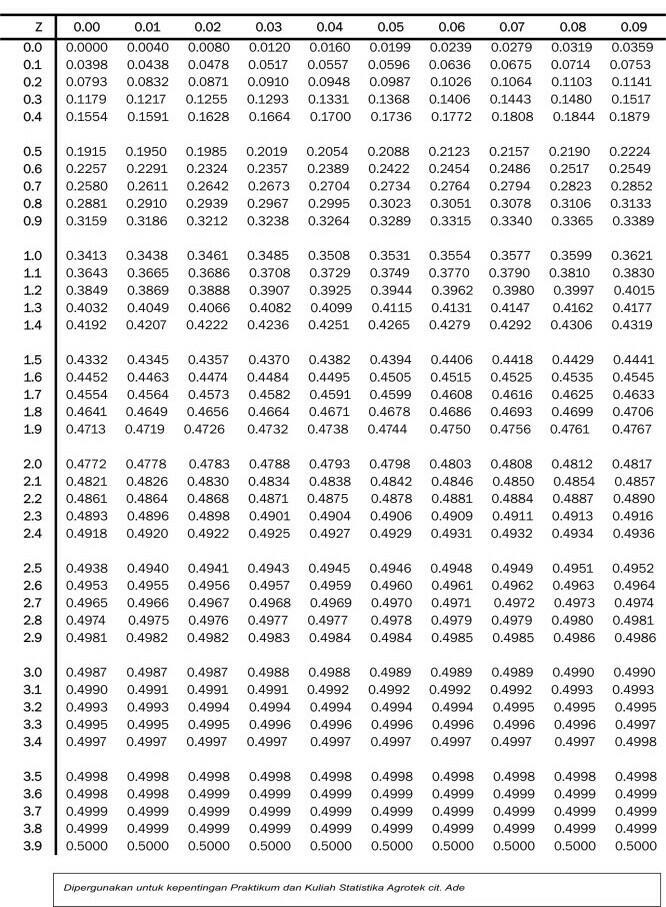
4. Menentukan Luas Daerah dengan Menggunakan Tabel Z
- Menghitung nilai Z sampai dua desimal.
- Menggambar kurva normal standar.
- Meletakkan nilai Z pada sumbu x kemudian menarik garis vertikal yang memotong kurva
- Nilai yang terdapat dalam daftar merupakan luas daerah antar garis tersebut dengan garis vertikal dititik 0
- Dalam daftar distribusi normal standar mencari tempat harga Z pada kolom paling kiri hanya sampai satu desimal dan mencari desimal kedua pada baris paling atas
- Dari Z ke kolom kiri maju ke kanan dan dari Z dibaris atau turun ke bawah, sehingga didapat bilangan yang merupakan luas daerah yang dicari.
Contoh:
1. Panjang roti yang diproduksi suatu pabrik berdistribusi normal dengan rata-rata 25cm dan simpangan baku 2cm. Berapa persen roti yang diproduksi dengan panjang kurang dari 23cm. Dalam soal disamping, µ = 25cm, σ = 2cm. Jika X meyatakan panjang roti yang diproduksi pabrik tersebut, soal ini menanyakan P[x < 23cm]. Yang ditanyakan ini dapat digambarkan sebagai berikut.
5. Ukuran Penyebaran
- Dispersi terdiri atas =
- Jangkauan
- Jangkauan antar kuartil
- Simpangan kuartil
6. Jangkauan/Rentang
Jangkauan atau rentang atau range adalah ukuran dispersi yang paling mudah ditentukan.
- J = Xmax – Xmin
- J = jangkauan/rentang/range
- Xmax = nilai tertinggi dari data
- Xmin = nilai terendah dari data
Contoh:
- DATA TUNGGAL
1. Diketahui data sebagai berikut :
3, 2, 3, 5, 5, 18, 10.Tentukan rangenya!
Jawab :
J = Xmax – Xmin
= 18 – 2
= 16
7. Jangkuan Antar Kuartil/Hamparan (H)
Jangkauan antar kuartil atau biasa disebut hamparan merukapan selisih dari kuartil 3 dan kuartil 1.
JAK = H
= K3 – K1
Contoh:
- DATA TUNGGAL
1. Diketahui data sebagai berikut :
6, 2, 3, 8, 9, 19, 11.Tentukan jangkauan antar kuartilnya!
Jawab :
Urutan data = 2, 3 (K1), 6, 8(K2), 9, 11(K3), 19.
JAK = K3 – K1
= 11– 3
= 8
8. Simpangan Kuartil (Qd)
Simpangan kuartil atau jangkauan semi antar kuartil adalah setengah dari jangkauan antar kuartil.
9. Simpangan Rata-rata (Deviasi Rata-rata)
Simpangan rata-rata atau deviasi rata-rata adalah suatu simpangan nilai tiap datum terhadap rataan hitungnya.
B. Standar Deviasi
- Standar deviasi atau simpangan baku adalah salah satu teknik statistic yang lazim digunakan untuk menjelaskan homogenesitas kelompok.
- Standar deviasi merupakan nilai statistik yang biasa digunakan untuk menentukan bagaimana sebaran data dalam sampel, serta seberapa dekat titik data individu ke mean atau rata-rata nilai sampel.
Fungsi Standar Deviasi
Standar deviasi umumnya dipakai oleh para ahli statistic atau orang yang terjun di dunia statistic untuk mengetahui apakah sampel data yang diambil mewakili seluruh populasi. Mencari data yang tepat untuk suatu populasi sangat sulit untuk dilakukan. Oleh karena itu dipakai sampel data yang mewakili seluruh populasi. Hal ini akan memudahkan seseorang untuk melakukan penelitian.
Rabu, 07 Maret 2018
Bagian 4
Kuartil, Desil, dan Persentil
1. Kuartil
a. Pengertian
Beberapa kumpulan data yang sudah diurutkan dari data terkecil hingga data terbesar atau sebaliknya yang kemudian dibagi menjadi empat bagian yang sama banyak.
Kuartil dibagi menjadi tiga macam yaitu K1, K2, K3. Pemberian nama ini ditentukan dari nilai kuartil yang paling kecil. (Andi, 2007)
b. Macam-macam Kuartil
-Kuartil Data Tunggal
1. Menyusun data dimulai dari data terkecil hingga data terbesar.
2. Menentukan letak kuartil yang diminta dengan menggunakan rumus



Keterangan:
Pi = persentil ke-
n = jumlah data
i = urutan persentil
-Persentil Data Berkelompok

b = tepi bawah kelas interval
p = panjang kelas interval
i = letak Psi
n = banyak data
Fk = frekuensi kumulatif sebelum kelas Psi
f = frekuensi kelas Psi
Kuartil, Desil, dan Persentil
1. Kuartil
a. Pengertian
Beberapa kumpulan data yang sudah diurutkan dari data terkecil hingga data terbesar atau sebaliknya yang kemudian dibagi menjadi empat bagian yang sama banyak.
Kuartil dibagi menjadi tiga macam yaitu K1, K2, K3. Pemberian nama ini ditentukan dari nilai kuartil yang paling kecil. (Andi, 2007)
b. Macam-macam Kuartil
-Kuartil Data Tunggal
1. Menyusun data dimulai dari data terkecil hingga data terbesar.
2. Menentukan letak kuartil yang diminta dengan menggunakan rumus

-Kuartil Dara Kelompok
2. Desil
Nilai atau angka yang membagi data yang menjadi 10 bagian yang sama, setelah disusun dari data terkecil hingga data terbesar atau sebaliknya. Dan desil hanya memiliki 9 nilai. Ada 2 (dua) kelompok desil. Yaitu nilai data desil yang belum dikelompokan (data tunggal) dan nilai data desil yang sudah
dikelompokkan (data berkelompok).
-Desil Data Tunggal

Dn = desil ke –
n = jumlah data
i = urutan desil
-Desil Data Berkelompok
3. Persentil
Nilai yang membagi data menjadi 100 bagian yang sama. Setelah disusun dari angka terkecil sampai ke yang terbesar. Harga persentil ada 99 bagian yaitu Ps1, Ps2, Ps3, ......., Ps99.
-Persentil Data Tunggal
Keterangan:
Pi = persentil ke-
n = jumlah data
-Persentil Data Berkelompok
b = tepi bawah kelas interval
p = panjang kelas interval
i = letak Psi
n = banyak data
Fk = frekuensi kumulatif sebelum kelas Psi
f = frekuensi kelas Psi
Rabu, 28 Februari 2018
Contoh Soal

1. Mean
Mean merupakan nilai rata-rata dari beberapa buah data. Nilai mean dapat ditentukan dengan cara membagi jumlah data dengan banyaknya data.
Untuk mendapatkan nilai dari Mean maka anda harus mencari tahu nilai tengah dan nilai hasil kali nilai tengah dengan frekuensi.

F1x1 adalah jumlah hasil dari nilai tengah di kali dengan frekuensi.
F1 adalah jumlah frekuensi.
F1 adalah jumlah frekuensi.


2. Modus
Modus merupakan nilai yang paling sering muncul. Apabila ada data data frekuensi, jumlah dari suatu nilai dari kumpulan data, maka bisa memakai modus.
Untuk bisa melihat hasil akhir dari modus maka kita harus menentukan
kelas pada tabel dengan memilih frekuensi yang paling banyak.
kelas pada tabel dengan memilih frekuensi yang paling banyak.


3. Median
Median adalah cara untuk menentukan letak tengah data setelah data disusun menurut urutan nilainya. Simbol untuk median ini yaitu Me.
Median adalah nilai data tengah, dalam data kelompok memiliki rumus yang sama dengan mencari Q2 ( Kuartil 2 ).


Senin, 19 Februari 2018
Bagian 2
Sorting dan Displaying Data
A. Pengertian Sorting
Sorting adalah sebuah metode untuk pengurutan data, misalnya dari data terbesar ke yang terkecil. Dengan cara program yang dibuat harus dapat membandingkan antar data yang diinputkan.
B. Macam-macam Metode Sorting
1. Metode Bubble Sort
yaitu metode atau algoritma pengaturan dengan cara melakukan penukaran data dengan tempat disebelahnya jika data sebelumnya lebih besar dari pada data sesudahnya secara terus menerus sampai bisa dipastikan dalam satu literasi tertentu tidak ada lagi perubahan atau telah terurut.
2. Metode Selection Sort
metode ini lebih efektif daripada metode bubble karena tidak memerlukan banyak pertukaran dan pengalokasian memori. Metode ini pada dasarnya memilih data yang akan diurutkan menjadi dua bagian yaitu bagian yang sudah diurutkan dan bagian yang belum diurutkan.
3. Metode Merge Sort
yaitu algoritma yang dijalankan sebagai akibat dari terlalu banyaknya daftar yang diurutkan dengan menghasilkan lebih banyak daftar yang diurutkan sebagai output.
4. Metode Quick Sort
suatu algoritma pengurutan data yang menggunakan teknik pemecahan data menjadi partisi-partisi, sehingga metode ini disebut juga dengan nama partition exchange sort.
C. Penyajian Data
Prinsip dasar penyajian data adalah komunikatif dan lengkap, dalam arti data yang disajikan dapat menarik perhatian pihak lain untuk membacanya dan mudah memahami isinya.
Ada beberapa cara penyajian data yaitu:
1. Tabel
Penyajian data hasil penelitian dengan menggunakan tabel merupakan penyajian yang banyak digunakan karena lebih efesien dan cukup komunikatif.
a) Tabel Biasa
Setiap tabel berisi judul tabel, judul setiap kolom, nilai data dalam setiap kolom, dan sumber data dari mana data tersebut diperoleh.
-Tabel Data Nominal
-Tabel Data Ordinal
-Tabel Data Interval
b) Tabel Distribusi Frekuensi
Tabel ini disusun bila jumlah data yang disajikan cukup banyak sehingga kalau disajikan dalam tabel biasa menjadi tidak efisien dan kurang komunikatif.
-Tabel Distribusi Frekuensi Kumulatif
-Tabel Distribusi Frekuensi Relatif
2. Grafik
Selain tabel, penyajian yang cukup populer dan komunikatif adalah grafik. Terdapat dua macam grafik yaitu grafik garis (polygon) dan grafik batang (histogram).
a) Grafik Garis
Biasanya dibuat untuk menunjukkan perkembangan suatu keadaan. Perkembangan tersebut bisa naik bisa turun. Hal yang perlu diperhatikan dalam membuat grafik adalah ketepatan membuat skala pada garis vertikal yang akan mencerminkan keadaan jumlah hasil observasi
b) Grafik Batang
Jika dalam grafik garis visualisasi data difokuskan pada garis grafik, sedangkan pada grafik batang visualisasi difokuskan pada luas batang. Namun kebanyakan penyajian data grafik batang, lebar batang dibuat sama sedangkan yang bervariasi adalah tingginya.
3. Diagram Lingkaran (Piechart)
Cara lain untuk menyaelitian adalah dengan diagram lingkaran. Diagram lingkaran digunakan untuk membandingkan data dari berbagai kelompok. Dibawah ini adalah salah satu contoh diagram lingkaran.
4. Pictogram
Pictogram adalah penyajian data statisyik dengan menggunakan lambang-lambang atau gambar tertentu yang mewakili objek yang diteliti.
Sorting dan Displaying Data
A. Pengertian Sorting
Sorting adalah sebuah metode untuk pengurutan data, misalnya dari data terbesar ke yang terkecil. Dengan cara program yang dibuat harus dapat membandingkan antar data yang diinputkan.
B. Macam-macam Metode Sorting
1. Metode Bubble Sort
yaitu metode atau algoritma pengaturan dengan cara melakukan penukaran data dengan tempat disebelahnya jika data sebelumnya lebih besar dari pada data sesudahnya secara terus menerus sampai bisa dipastikan dalam satu literasi tertentu tidak ada lagi perubahan atau telah terurut.
2. Metode Selection Sort
metode ini lebih efektif daripada metode bubble karena tidak memerlukan banyak pertukaran dan pengalokasian memori. Metode ini pada dasarnya memilih data yang akan diurutkan menjadi dua bagian yaitu bagian yang sudah diurutkan dan bagian yang belum diurutkan.
3. Metode Merge Sort
yaitu algoritma yang dijalankan sebagai akibat dari terlalu banyaknya daftar yang diurutkan dengan menghasilkan lebih banyak daftar yang diurutkan sebagai output.
4. Metode Quick Sort
suatu algoritma pengurutan data yang menggunakan teknik pemecahan data menjadi partisi-partisi, sehingga metode ini disebut juga dengan nama partition exchange sort.
C. Penyajian Data
Prinsip dasar penyajian data adalah komunikatif dan lengkap, dalam arti data yang disajikan dapat menarik perhatian pihak lain untuk membacanya dan mudah memahami isinya.
Ada beberapa cara penyajian data yaitu:
1. Tabel
Penyajian data hasil penelitian dengan menggunakan tabel merupakan penyajian yang banyak digunakan karena lebih efesien dan cukup komunikatif.
a) Tabel Biasa
Setiap tabel berisi judul tabel, judul setiap kolom, nilai data dalam setiap kolom, dan sumber data dari mana data tersebut diperoleh.
-Tabel Data Nominal
-Tabel Data Ordinal
-Tabel Data Interval
b) Tabel Distribusi Frekuensi
Tabel ini disusun bila jumlah data yang disajikan cukup banyak sehingga kalau disajikan dalam tabel biasa menjadi tidak efisien dan kurang komunikatif.
-Tabel Distribusi Frekuensi Kumulatif
-Tabel Distribusi Frekuensi Relatif
2. Grafik
Selain tabel, penyajian yang cukup populer dan komunikatif adalah grafik. Terdapat dua macam grafik yaitu grafik garis (polygon) dan grafik batang (histogram).
a) Grafik Garis
Biasanya dibuat untuk menunjukkan perkembangan suatu keadaan. Perkembangan tersebut bisa naik bisa turun. Hal yang perlu diperhatikan dalam membuat grafik adalah ketepatan membuat skala pada garis vertikal yang akan mencerminkan keadaan jumlah hasil observasi
b) Grafik Batang
Jika dalam grafik garis visualisasi data difokuskan pada garis grafik, sedangkan pada grafik batang visualisasi difokuskan pada luas batang. Namun kebanyakan penyajian data grafik batang, lebar batang dibuat sama sedangkan yang bervariasi adalah tingginya.
3. Diagram Lingkaran (Piechart)
Cara lain untuk menyaelitian adalah dengan diagram lingkaran. Diagram lingkaran digunakan untuk membandingkan data dari berbagai kelompok. Dibawah ini adalah salah satu contoh diagram lingkaran.
4. Pictogram
Pictogram adalah penyajian data statisyik dengan menggunakan lambang-lambang atau gambar tertentu yang mewakili objek yang diteliti.
Kamis, 08 Februari 2018
Bagian 1
Statistika & Penelitian
A. Pengertian
Statistika = metode.
Statistik = hasil dari metode.
Penelitian : cara ilmiah untuk mendapatkan data dengan tujuan dan kegunaan tertentu.
Statistika digunakan dalam penelitian sebagai metode untuk mendapatkan dan mengolah data.
Selain itu, statistika digunakan untuk:
1. Menghitung jumlah populasi penduduk
2. Perpajakan
3. Hitung cepat
4. Penilaian
5. Menguji kesulitan soal
6. Menghitung IQ
B. Variabel & Paradigma Penelitian
Variabel Penelitian adalah suatu nilai dari orang, objek, atau kegiatan yang mempunyai variasi tertentu dan ditetapkan oleh peneliti untuk dipelajari dan ditarik kesimpulannya.
Variabel dibagi menjadi 5 macam:
1. Variabel Independen (stimulus, prediktor, antecedent)
Variabel yang menjadi sebab timbulnya variabel dependen.
2. Variabel Dependen (output, kriteria, konsekuen)
Variabel yang menjadi akibat karena adanya variabel independen.
3. Variabel Moderator
Variabel yang memperkuat atau memperlemah hubungan antara variabel independen dan dependen.
4. Variabel Intervening
Variabel yang secara tidak langsung mempengaruhi variabel independen dan dependen serta tidak dapat dihitung atau diukur.
5. Variabel Kontrol
Variabel konstan sehingga pengaruh variabel independen terhadap dependen tidak dipengaruhi oleh faktor luar yang tidak teliti.
Paradigma Penelitian atau Model Penelitian adalah pola hubungan antara variabel yang akan diteliti.
Paradigma Penelitian dibagi menjadi 7 macam:





Proses Penelitian

C. Peranan Statistika dalam Penelitian
1. Alat untuk menghitung besarnya anggota sampel yang diambil dalam suatu populasi.
2. Alat untuk menguji validitas dan reliabilitas instrumen.
3. Teknik penyajian data agar lebih komunikatif, dapat dalam bentuk tabel, diagram, grafik, dan lain-lain.
4. Alat untuk menguji hipotesis yang diajukan.
D. Macam-macam Statistik
1. Statistik Deskriptif
digunakan untuk menganalisis suatu statistik hasil penelitian tetapi tidak digunakan untuk membuat kesimpulan atau generalisasi.
2. Statistik Interferensial
digunakan untuk menganalisis data sampel, dan hasilnya akan digeneralisasikan untuk populasi dimana sampel itu diambil. Statisyik interferensial dibagi lagi menjadi dua, yaitu:
a. Statistik Parametris→menganalisis data interval atau rasio yang diambil dari populasi yang berdistribusi normal.
b. Statistik Non Parametris→digunakan untuk menganalisis data nominal dan ordinal dari populasi yang bebas distribusi. Jadi tidak harus normal.
E. Macam-Macam Data Penelitian
Data hasil penelitian dibagi menjadu dua, yaitu:
1. Data Kualitatif→data berbentuk kalimat, kata, atau gambar.
2. Data Kuantitatif→data berbentuk angka atau skoring.
Data Kuantitatif dibagi menjadi dua:
•Data Diskrit→data yang diperoleh dari hasil menghitung bukan mengukur atau survey.
•Data Kontinum→data yang diperoleh dari hasil pengukuran.
Data Kontinum dibagi menjadi tiga, yaitu:
-Data Ordinal: data yang berjenjang atau berbentuk peringkat.
-Data Interval: data yang jaraknya sama tetapi tidak memiliki nilai nol absolut (mutlak).
-Data Rasio: data yang jaraknya sama dan mempunyai nilai nol absolut. Jadi, kalau data nol berarti tidak ada apa-apanya.
Statistika & Penelitian
A. Pengertian
Statistika = metode.
Statistik = hasil dari metode.
Penelitian : cara ilmiah untuk mendapatkan data dengan tujuan dan kegunaan tertentu.
Statistika digunakan dalam penelitian sebagai metode untuk mendapatkan dan mengolah data.
Selain itu, statistika digunakan untuk:
1. Menghitung jumlah populasi penduduk
2. Perpajakan
3. Hitung cepat
4. Penilaian
5. Menguji kesulitan soal
6. Menghitung IQ
B. Variabel & Paradigma Penelitian
Variabel Penelitian adalah suatu nilai dari orang, objek, atau kegiatan yang mempunyai variasi tertentu dan ditetapkan oleh peneliti untuk dipelajari dan ditarik kesimpulannya.
Variabel dibagi menjadi 5 macam:
1. Variabel Independen (stimulus, prediktor, antecedent)
Variabel yang menjadi sebab timbulnya variabel dependen.
2. Variabel Dependen (output, kriteria, konsekuen)
Variabel yang menjadi akibat karena adanya variabel independen.
3. Variabel Moderator
Variabel yang memperkuat atau memperlemah hubungan antara variabel independen dan dependen.
4. Variabel Intervening
Variabel yang secara tidak langsung mempengaruhi variabel independen dan dependen serta tidak dapat dihitung atau diukur.
5. Variabel Kontrol
Variabel konstan sehingga pengaruh variabel independen terhadap dependen tidak dipengaruhi oleh faktor luar yang tidak teliti.
Paradigma Penelitian atau Model Penelitian adalah pola hubungan antara variabel yang akan diteliti.
Paradigma Penelitian dibagi menjadi 7 macam:





Proses Penelitian

C. Peranan Statistika dalam Penelitian
1. Alat untuk menghitung besarnya anggota sampel yang diambil dalam suatu populasi.
2. Alat untuk menguji validitas dan reliabilitas instrumen.
3. Teknik penyajian data agar lebih komunikatif, dapat dalam bentuk tabel, diagram, grafik, dan lain-lain.
4. Alat untuk menguji hipotesis yang diajukan.
D. Macam-macam Statistik
1. Statistik Deskriptif
digunakan untuk menganalisis suatu statistik hasil penelitian tetapi tidak digunakan untuk membuat kesimpulan atau generalisasi.
2. Statistik Interferensial
digunakan untuk menganalisis data sampel, dan hasilnya akan digeneralisasikan untuk populasi dimana sampel itu diambil. Statisyik interferensial dibagi lagi menjadi dua, yaitu:
a. Statistik Parametris→menganalisis data interval atau rasio yang diambil dari populasi yang berdistribusi normal.
b. Statistik Non Parametris→digunakan untuk menganalisis data nominal dan ordinal dari populasi yang bebas distribusi. Jadi tidak harus normal.
E. Macam-Macam Data Penelitian
Data hasil penelitian dibagi menjadu dua, yaitu:
1. Data Kualitatif→data berbentuk kalimat, kata, atau gambar.
2. Data Kuantitatif→data berbentuk angka atau skoring.
Data Kuantitatif dibagi menjadi dua:
•Data Diskrit→data yang diperoleh dari hasil menghitung bukan mengukur atau survey.
•Data Kontinum→data yang diperoleh dari hasil pengukuran.
Data Kontinum dibagi menjadi tiga, yaitu:
-Data Ordinal: data yang berjenjang atau berbentuk peringkat.
-Data Interval: data yang jaraknya sama tetapi tidak memiliki nilai nol absolut (mutlak).
-Data Rasio: data yang jaraknya sama dan mempunyai nilai nol absolut. Jadi, kalau data nol berarti tidak ada apa-apanya.
Langganan:
Komentar (Atom)